변수의 자료형에 따른 분류 방법
- describe()
- value_counts()
- nunique()
수치형 변수 탐색
평균,중앙값,분산,왜도,첨도- 시각적 분포 활용 -> 히스토그램, KDE 플롯
컬럼별 Dtype 값 출력
data.dtype()
# object, int64, float64,,
data.dtype.value_counts()
# object 20
# int64 20
# float64 19
# ...각각의 변수들을 그룹으로 카운트하여 확인
data['column_1'].value_counts()
# column_1 count
# test A 1
# test B 5
# test C 6종류의 총 갯수
data['column_1'].nunique() # 3
# "test A", "test A", "test A" => 총 3개수치형 변수 활용
for col in numeric_col:
print(col, '----------------')
print('평균', data[col].mean())
print('중앙값', data[col].median())
print('표준편차', data[col].std())
print('최대값', data[col].max())
print('최소값', data[col].min())
print('외도', data[col].skew())
print('첨도', data[col].kurt())
q1 = data[col].quantile(0.25)
q3 = data[col].quantile(0.75)
iqr = q3 - q1
print('1사분위수',q1)
print('3사분위수',q3)
print('사분위 범위',iqr)수치형 변수 시각화
- 히스토그램
import matplotlib.pyplot as plt
import seaborn as sns
plt.hist(data['numeric_column'], bins=20)
# bins 파라미터 값으로 변경해서 표의 모양을 바꾸는 것은 그렇게 좋진 않습니다.
# 이유 => bins를 줄이면 큼직하게 보이므로 상승하는 것처럼 보이는 구간이 bins를 줄이면 상승과 하락이 많을 수 있습니다.- KDE
연속형 데이터를 대상으로 하기 때문에 결측치, null 값이 있으면 안됩니다.
# 연속형 데이터를 대상으로 하기 때문에 결측치, null 값이 있으면 안됩니다.
sns.kdeplot(data['numeric_column'])범주형 변수 탐색
- Pandas의 plot
data['categorical_column'].value_counts().plot(kind='bar')- seaborn의 plot
sns.countplot(data=data, x='categorical_column')- matplotlib의 plot
plt.figure(figsize=(8,6))
ax = sns.countplot(data=data, x='categorical_column')
for p in ax.patches:
ax.annotate(f'{p.get_height()}',(p.get_x() + p.get_width() / 2, p.get_height()),
ha='center', va='center', xytext=(0, 5), textcoords='offset points')
plt.title('Distribution of Categorical Column')
plt.show()범주의 수가 많거나 불균형할 때의 분석전략
corr() 함수로 상관계수를 구해서 전체 변수 간 상관 구조를 파악
수치형 변수간 상관관계
스피어만,피어슨
- 스피어만 상관계수
수치형 + 범주형 일부 범주형 데이터는 수치형(categorical)을 가질 수 있는 성격을 띈 데이터 (ex. 좋음, 보통, 나쁨 = 2, 1, 0)
data_spearman_corr = data[numeric_column].corr(method='spearman')
display(data_spearman_corr)
- 피어슨 상관계수
수치형 데이터 대상으로 수치 구현
data_spearman_corr = data[numeric_column].corr(method='spearman')
display(data_spearman_corr)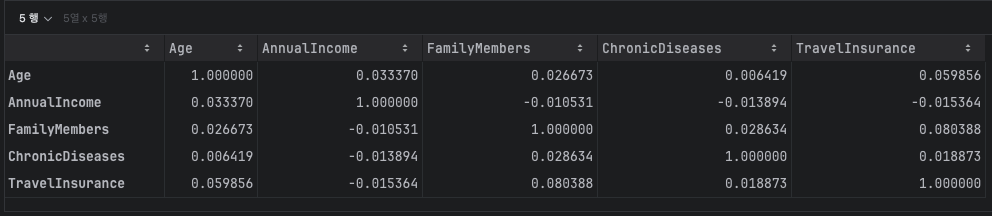
수치형 범주형 관계
박스 플롯, 스트립 플롯
박스 플롯
수치형, 범주형 데이터 처리
data.boxplot(column='Age', by='Employment Type')
plt.show()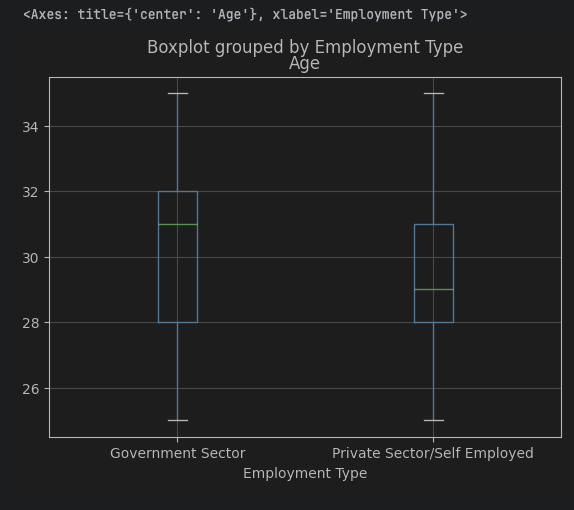
스프릿 플롯
sns.stripplot(x='Employment Type', y='Age', data=data, jitter=True)
변수 관계 이상치 탐색 및 해석
데이터의 시각적 이상치 확인
이상치가 있는 변수의 데이터 표준화
from sklean.preprocess inport StandardScaler
s = StandardScaler()
data['Annuallncome_s'] = s.fit_transform(data[['Annuallencom ']])
# 이상치 탐색
q1 = data['Annuallncome_s'].quantile(0.25)
q3 = data['Annuallncome_s'].quantile(0.75)
iqr = q3 - q1
lower_bound = q1 - 1.5 - iqr
upper5_bound = q3 + 1.5 + iqr
outliers= data[(data['Annuallencom '] < lower_bound) | (data['Annuallencom '] > upper5_bound)]
outliers # 44.575,,,그럼에도 outliers가 나옴,, StandardScaler()로 스케일이 잘 안되는 것으로 판단
로그변환으로 처리하여 이상치 변수 처리
,,,
data['Annuallncome_s'] = np.log(data['Annuallncome'])
,,,outliers 데이터를 시각화해서 얼마나 다른 값과 차이가 있는지 확인
산점도(Scatter plot)
sns.scatterplot(data=data, x='Age", y='Annuallncome')